Tous les Projets
35+ projets ML dans tous les domaines — tous de qualité production, entièrement documentés
56 projets au total
 En Vedette
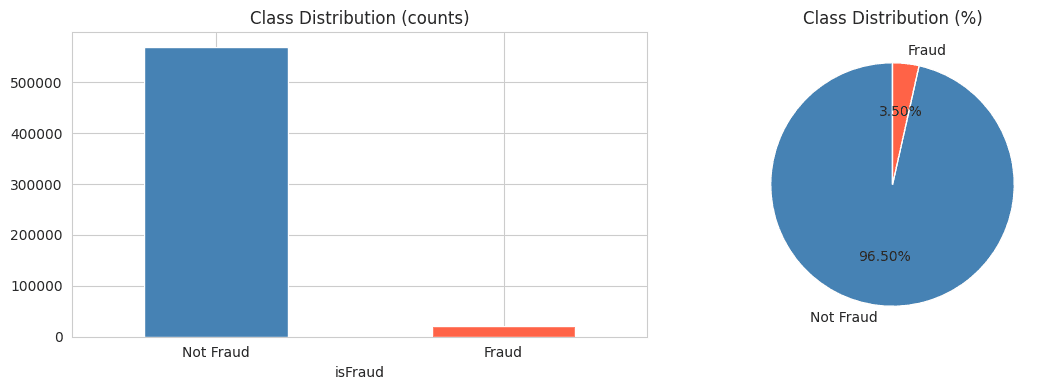
En VedetteDétection de Fraude IEEE-CIS
Pipeline ML complet sur 590K transactions, 433 caractéristiques. LightGBM AUC 0.9648 — ensemble de stacking LGB+XGB+CatBoost+RF avec ingénierie de caractéristiques comportementales avancées.
Plateforme de Génération d'Images IA (Ofoto)
Déploiement en production de Stable Diffusion (Automatic1111 + ControlNet) avec backend FastAPI, frontend Vue.js — 500+ requêtes simultanées, 99,9% disponibilité, -35% latence, -40% temps de release.
Agent Commercial IA sur WhatsApp
Agent IA de vente sur WhatsApp Business. Classifie les messages (Vente/Support/Hors-sujet), interroge la BD Supabase, utilise Ollama/Llama3.1 localement, bilingue FR/AR, mémoire conversationnelle. -90% du temps de traitement manuel.
 En Vedette
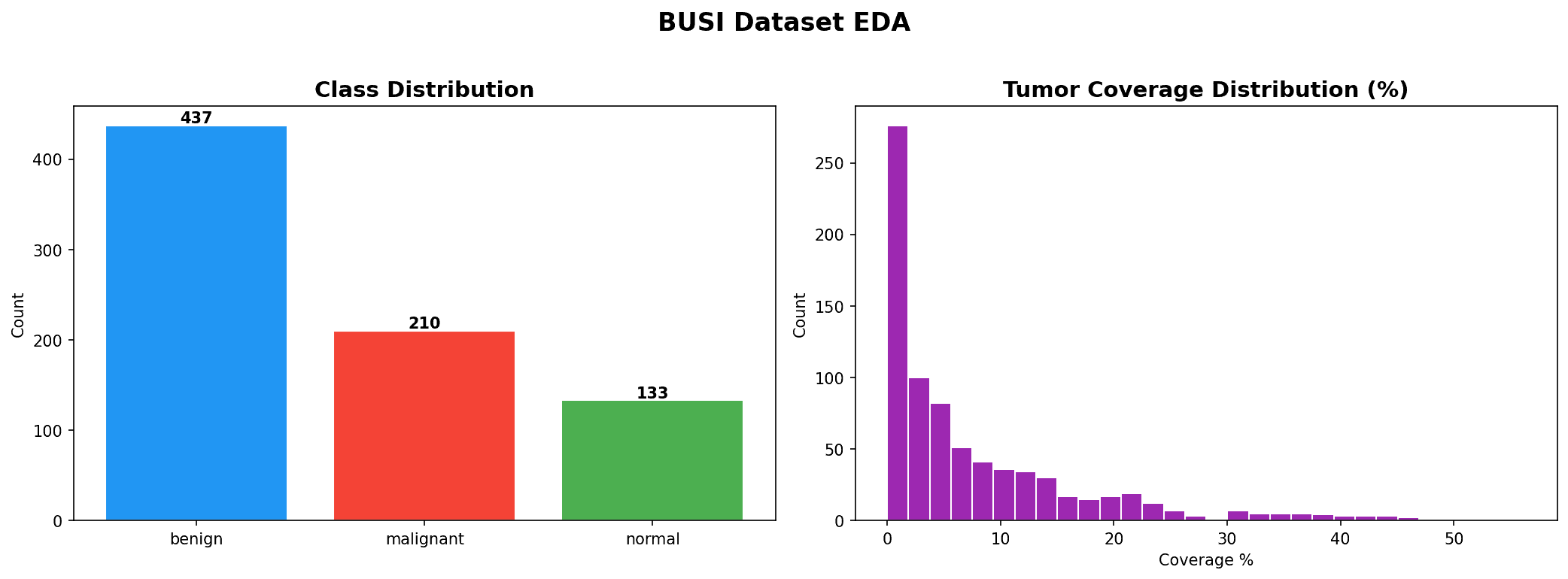
En VedetteSegmentation d'Échographies du Cancer du Sein
Benchmark de 9 architectures de segmentation sur 780 images BUSI. DeepLabV3+ en tête avec Dice 0,7863, IoU 0,6483. FCN → SimpleUNet → SegNet → Attention-UNet → TransUNet → ResNet34-UNet → EfficientNet-UNet → DeepLabV3+ → Swin-UNet.
 En Vedette
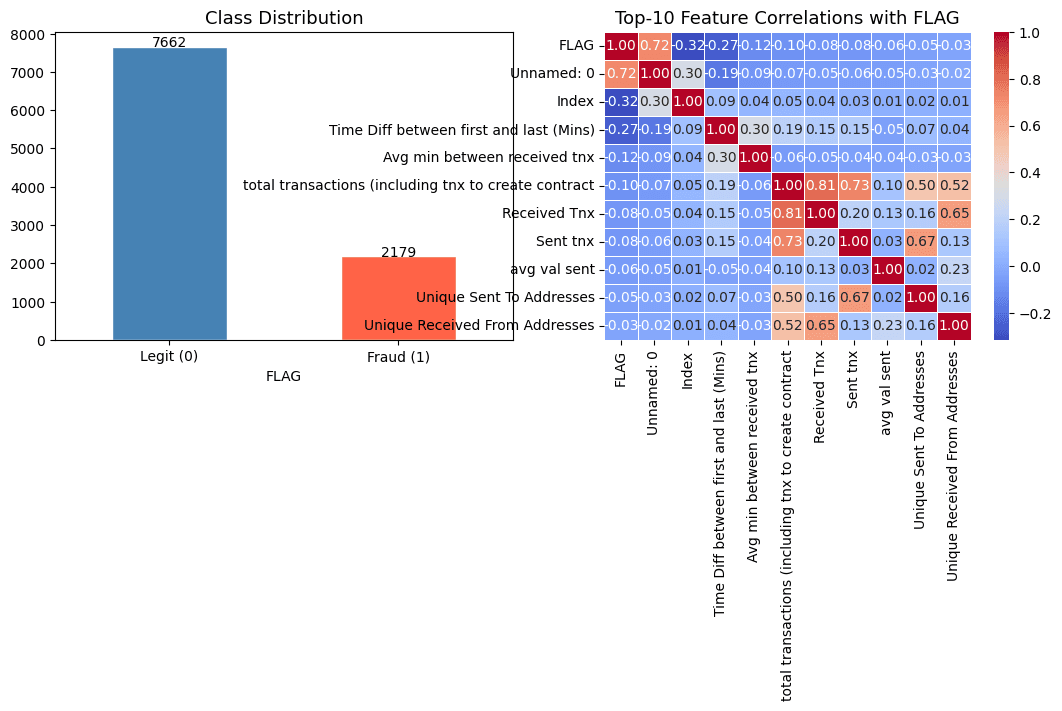
En VedetteDétection de Fraude sur la Blockchain Ethereum
Détection de fraude blockchain sur 9 841 adresses Ethereum. XGBoost+LightGBM+CatBoost+Stacking avec Optuna HPO (40 essais) et SHAP. AUC 0,9973, F1 0,9658 au seuil optimal 0,85.
 En Vedette
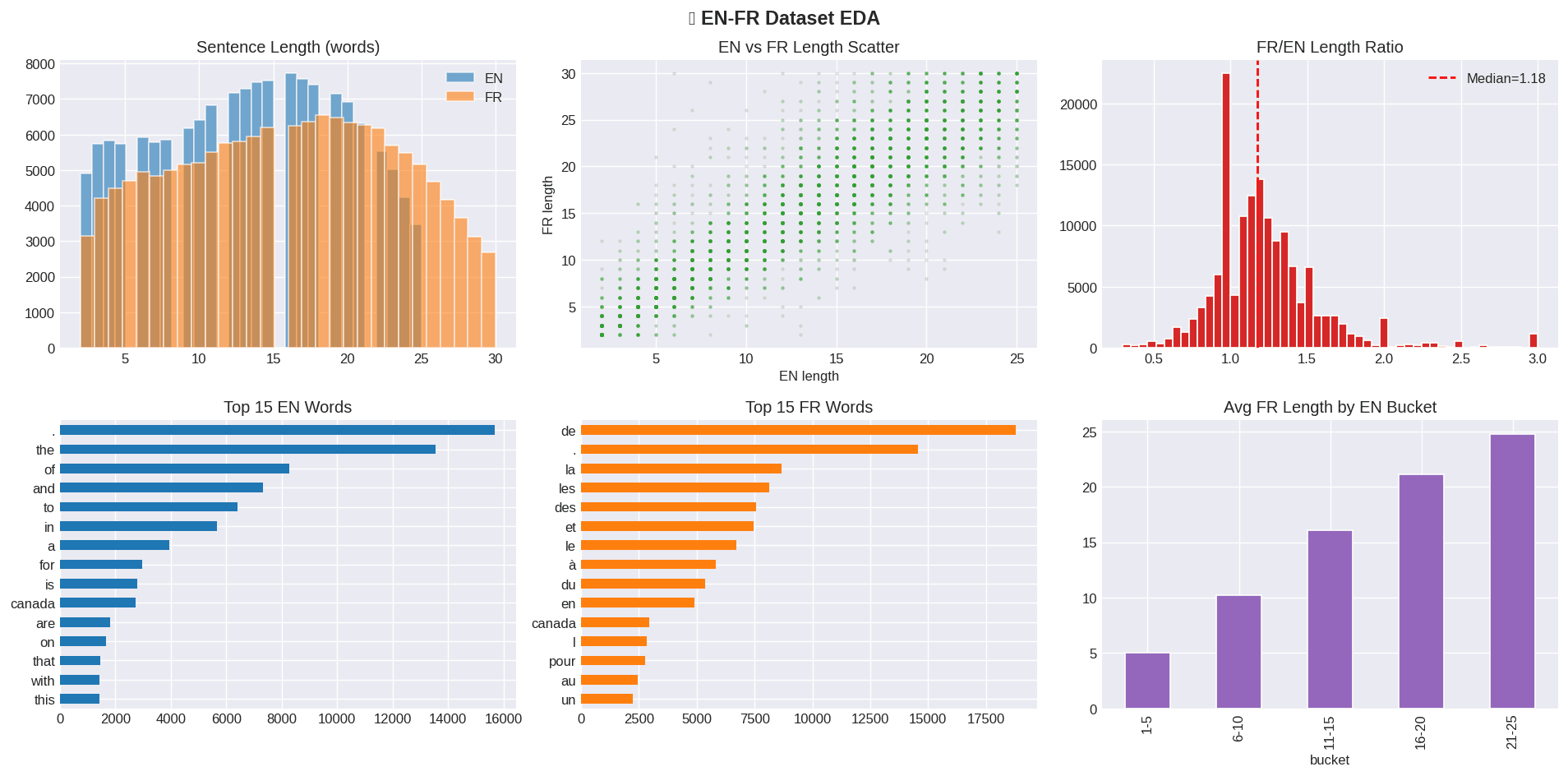
En VedetteTraduction Automatique Neuronale Anglais → Français
NMT économe en mémoire sur un dataset de 6 Go sans crash RAM. Seq2Seq personnalisé + fine-tuning HuggingFace mBART/Helsinki-NLP. Correction de 5 bugs critiques en amont (GradientTape, overflow tokenizer, API dépréciée).

Analyse de Sentiment Twitter
Pipeline NLP de 6 modèles sur 74K tweets. DistilBERT atteint 96,6% de précision. LR+TF-IDF à 85%. LSTM/Bi-LSTM/CNN atteignent 87–88%. 4 classes : Positif, Négatif, Neutre, Non pertinent.

Détection de Fausses Nouvelles
Pipeline NLP de 13 modèles sur 44 898 articles. Soft Voting Ensemble & Stacking atteignent 99,86% de précision, AUC=1,0. Seulement 2 erreurs sur l'ensemble de test complet. DistilBERT à 99,87% sur 6K sous-ensemble.

Reconnaissance d'Activité Humaine (HAR)
Benchmark de 14 modèles sur 9 299 lectures de capteurs UCI. SVM linéaire en tête à 96,1%. t-SNE montre des clusters d'activité nets. PCA retient 95% de variance à ~95 composantes. Confusion Assis/Debout est la principale source d'erreurs.

Prédiction de Résiliation Client Télécom
Pipeline churn en 3 phases sur 7 043 clients. XGBoost optimisé Optuna : AUC 0,8484, F1 0,5947. Phase 1 : 5 baselines → Phase 2 : ensembles de boosting → Phase 3 : 100 essais Optuna + SHAP. Durée d'abonnement & type de contrat dominent.

Fraude aux Réclamations d'Assurance Véhicule
Pipeline de fraude de 16 modèles pour 15 420 réclamations (5,99% de fraude). AdaBoost maximise le rappel (89,2%). XGBoost RandomizedSearchCV : CV AUC 0,9847. SHAP : Fault (37,9%) est le principal indicateur de fraude.

Recherche de Personnes par Reconnaissance Faciale
Reconnaissance faciale zero-shot avec embeddings ResNet-50 (VGGFace2) préentraînés. Recherche de 13 233 images LFW via distance euclidienne 128D. 18/19 correspondances correctes au seuil 0,55. Aucun entraînement requis.

Reconnaissance des Émotions Faciales
Reconnaissance de 7 émotions sur RAF-DB (12 271 images). Ensemble ResNet50+ViT-Small+EfficientNetB3 atteint 86,57%. Apprentissage par transfert en 2 phases. GradCAM confirme la focalisation sur bouche/sourcils/yeux.

Détection de Stationnement Intelligent YOLOv8
Occupation des places de stationnement (libre vs occupée) avec YOLOv8n. Test mAP50=0,942, mAP50-95=0,798. Arrêt anticipé à l'époque 74. 30 images annotées CVAT (22/4/4). Inférence : 9 libres + 21 occupées par lot @ 41,2ms.

Détection du Cancer — YOLOv8 (n/s/m)
Benchmark de 3 variantes YOLOv8 pour la localisation du cancer. YOLOv8m : test mAP50=0,6782, Précision=0,7633, F1=0,6941. 1 968 images d'entraînement. Export ONNX (49,8 Mo) + TorchScript (99,1 Mo).

Détection d'Animaux YOLOv8
Détection d'animaux en 80 classes avec YOLOv8n. mAP@0,5=0,668, mAP@0,5:0,95=0,560. Meilleur : Tigre (0,967), Moineau (0,953). Difficile : Calmar (0,009). ONNX (12,3 Mo). 29 071 images pour 80 espèces.

Classification des Maladies des Plantes
Benchmark PlantVillage à 15 classes. MobileNetV2 meilleur individuel : 92,86%. Ensemble (MobileNetV2+EfficientNetB3+ResNet50) test : 83,43%. Déséquilibre 42,5×. Correction d'un bug de réinitialisation du générateur qui causait l'effondrement de l'ensemble.

Classification d'Espèces de Papillons
Pipeline multi-modèle en 4 phases pour la classification de 75 espèces. CNN vanille → TL préentraîné → architecture hybride parallèle/séquentielle → têtes auxiliaires multi-perte. Grad-CAM confirme la focalisation sur les motifs d'ailes.

Classification du Cancer sur Scanner CT Thoracique
Classification du cancer pulmonaire en 4 classes sur 613 images CT. MobileNetV2 meilleur : 66,03% de précision test. 16 modèles : HOG+8 classiques + CNN personnalisés + TL. MC-Dropout signale les cas incertains pour révision par radiologue.

Détection et Segmentation de Déchets TACO
Benchmark de 5 modèles sur 1 500 images de déchets (4 784 annotations, 60 catégories). RT-DETR-L meilleur : mAP50=0,2778, Précision=0,4833. Perte Faster R-CNN converge de 0,76→0,11. YOLOv8n/s/l + RT-DETR + Faster R-CNN.

Classification des Chiffres en Langue des Signes
CNN pour la reconnaissance de chiffres en langue des signes (0–9) sur 2 062 images équilibrées. 96,13% de précision de validation à l'époque 23, F1 entraînement=0,98. CNN à 3 couches avec BatchNorm + Dropout. Exporté en H5 pour déploiement.

Classification du Cancer du Sein (Wisconsin)
Benchmark de 14 modèles sur le dataset Wisconsin (569 échantillons). Voting Ensemble : 99,12% de précision. CatBoost : AUC 0,9990. Extra Trees : 98,25%. RF + SVM ajustés via RandomizedSearchCV/GridSearchCV. SHAP : concave_points_worst domine.

Systèmes de Recommandation de Livres — Taxonomie Complète
Taxonomie complète des systèmes de recommandation sur BookCrossing (1,1M d'évaluations) : User-CF, Item-CF, SVD/NMF/ALS, basé contenu, hybride, NCF, AutoRec, GRU4Rec. User-CF RMSE 1,6645, P@10 0,6629, R@10 0,6910.

Prévision de la Consommation d'Énergie Horaire
Benchmark de 10 modèles sur 145 366 enregistrements horaires PJM (2002–2018). LightGBM meilleur : MAE=210,8 MW, RMSE=285,4 MW, MAPE=0,66%. Prophet échoue (MAPE=10,25%). BiLSTM MAPE=2,17%. 26 caractéristiques lag/rolling/cycliques.

Prévision EURUSD — 30+ Modèles (Quantique · GNN · Diffusion · AG)
Benchmark EURUSD le plus complet : 30+ modèles dont ML Quantique (QSVM/QNN/QAE/VQC), Algorithmes Génétiques (7 variantes + Chromosomes Neuronaux), GNN, Neural SDE, Diffusion DDPM, Informer, PatchTST, TFT. Méthodologie delta-target. Optimisation multi-objectif NSGA-2.

Prédiction de l'Épidémie de COVID-19
Pipeline sans fuite sur 188 enregistrements quotidiens (Jan–Jul 2020). Cible = nouveaux cas quotidiens (stationnaire). CV Walk-forward TimeSeriesSplit. Modèle SEIR + ARIMA + XGBoost + LSTM + Transformer. Corrige la fuite sur les données cumulées.

Détection de Motifs Météorologiques
Pipeline à 9 méthodes sur 96 453 enregistrements horaires. K-Means (sil=0,45, K=3), DBSCAN, Isolation Forest (1 930 anomalies), LightGBM macro F1=0,74, 1D-CNN 94,85%, LSTM Autoencoder, Prophet (16 jours d'anomalies).

ML sur la Chaîne d'Approvisionnement DataCo
ML sans fuite sur 180 519 commandes. LightGBM AUC 0,8563 (livraison tardive). Gradient Boosting R²=0,9996 (régression profit). Suppression des colonnes post-exécution qui gonflent à AUC=1,0 dans la plupart des solutions publiées.

Pipeline ML sur Offres d'Emploi LinkedIn
Pipeline ML complet sur 123 849 offres LinkedIn (2023–2024). Prédiction de salaire, analyse de demande de compétences (213K paires), NLP sur descriptions. 7 fichiers CSV joints. Normalisation des périodes de paye (horaire→annuel).

Jeux Avancés — Deep RL
Double Dueling DQN + PER (SumTree). CartPole-v1 résolu à l'épisode 300 (MA-100=441,1, meilleure éval 497,2/500). LunarLander-v3 résolu à l'épisode 207 (MA-100=202). Réseau de 134 275 paramètres avec LayerNorm.

Détection d'Anomalies Réseau IoT
Détection d'intrusion sur systèmes embarqués avec déséquilibre extrême (10% anomalies). BiLSTM+Attention : PR-AUC=0,186, Rappel=33,3%. Augmentation 5× (Gaussien/MixUp/masquage). Incertitude MC-Dropout. Perte focale.

Génération de Poésie — BERT / GPT-2 / T5 Fine-tuné
Fine-tuning de BERT, GPT-2 et T5 sur le corpus Poetry Foundation pour la génération créative de poèmes. 10 checkpoints sauvegardés. Analyse de diversité lexicale par poète. Beam search + sampling par température. Dashboard comparant les 3 architectures.

Reconnaissance de Noms Manuscrits
Benchmark OCR sur 66K images. TrOCR (ViT+GPT-2, 334M) meilleur : CER=0,0481, 80% de correspondance exacte. CRNN-ResNet34 : CER=0,0502. Optimisations AMP + torch.compile + accumulation de gradients.

Prédiction du Temps de Livraison Alimentaire
Benchmark de régression sur 16 modèles. La Régression Linéaire gagne étonnamment : RMSE=8,76 min, R²=0,829. XGBoost ajusté : RMSE=9,19. Distance & trafic dominent. Caractéristiques d'interaction capturent les non-linéarités.

Prévision de la Consommation Électrique des Ménages
Séries temporelles multi-modèles sur 2,9M enregistrements UCI (2006–2010). ARIMA, SARIMA, Prophet, LSTM sur Global_active_power. STL révèle des motifs quotidiens+hebdomadaires. Ensemble avec pondération inverse-RMSE.

Prévision Historique de la Demande de Produits
Benchmark de 19 modèles : TS classique → ML → DL → ensemble. CatBoost R²=0,7125 (meilleur). ML écrase TS classique (SMAPE 115–130% vs 35–40% pour TS, mais R² négatif pour TS). CV walk-forward avec Optuna.

Classification de Commandes Vocales Synthétiques
CNN audio à 30 classes atteint 100% de précision test sur 41 849 échantillons. Mel-spectrogram (64 bins) + SpecAugment. CNN à 4 blocs, 1,25M paramètres. Précision val atteint 100% à l'époque 8. Label smoothing 0,1.

Détection de Lignes (Vision par Ordinateur)
Benchmark de CV classique : Hough Standard (2,53ms, 22 lignes), Hough Probabiliste (4,29ms, 47 segments), LSD (23,98ms, 422 segments). Hough 6–10× plus rapide. Images dashcam Udacity + images synthétiques. Pipeline HSV+ROI.
Génération de Visages Anime (DCGAN)
DCGAN entraîné 100 époques sur Tesla T4 sur 43K images anime. Pile ConvTranspose2d (100→512→256→128→64→3). β₁=0,5, lissage des étiquettes, StepLR. Interpolation latente slerp pour des transitions fluides.
Moteur de Recommandation E-commerce (n8n)
Backend de recommandation en production : n8n + PostgreSQL, 4 modes (tendances/co-achat/personnalisé/réachat), 74 nœuds, API webhook, planificateur quotidien. Aucun serveur personnalisé requis.
Système Multi-Agents RAG (n8n + Pinecone)
n8n à 109 nœuds : PDF Google Drive → store vectoriel Pinecone → embeddings Cohere → Agent IA Ollama → scraping Airtop → acteurs Apify. 5 sous-workflows. RAG complet + mémoire conversationnelle.
Architecture Microservices (Spring Boot)
Microservices de production : Spring Boot, streaming d'événements Apache Kafka, auth OAuth2/Keycloak, appels inter-services gRPC, passerelle API, Docker. Conception orientée événements avec isolation PostgreSQL par service.
Plateforme RH IA — 20 outils LLM, ATS & MCP
Plateforme RH complète propulsée par gpt-oss:120b (Ollama Cloud) : 20 outils IA sur 7 domaines RH, pipeline ATS persistant, assistant data langage-naturel→SQL, pré-entretien vocal, automatisation Gmail et serveur MCP — FastAPI + SQLite, multilingue FR/EN/AR/Darija.
Plateforme de Conférences — Microservices Spring Cloud
Système de microservices Spring Cloud complet pour conférences & keynotes : Config Server, découverte Eureka, API Gateway, deux resource servers JWT sécurisés par Keycloak (OAuth2/OIDC), appels inter-services OpenFeign avec propagation de token, et un client Angular.
Microservices Sécurisés — OAuth2 / OIDC / Keycloak
Microservices e-commerce sécurisés où Keycloak est le serveur d'autorisation central. Deux resource servers Spring Boot (inventaire, commandes) valident les JWT émis par Keycloak ; order-service appelle inventory via OpenFeign avec propagation du token ; un client Angular se connecte via OIDC.
Streaming d'Événements Temps Réel — Kafka + Spring Cloud Stream
Traitement fonctionnel de flux d'événements avec Spring Cloud Stream et Kafka Streams : un supplier produit des page-events, une function les transforme, et un pipeline KStream applique des fenêtres glissantes de 5 s pour des analytics par page en temps réel diffusées au navigateur via Server-Sent Events.
Service Multi-Connecteurs — REST · GraphQL · SOAP · gRPC
Un même service métier exposé simultanément via quatre styles de communication — REST, GraphQL, SOAP et gRPC — puis consommé par un second microservice en REST (OpenFeign) et gRPC. Une étude comparative des protocoles d'API sur le même domaine Customer.
Microservice de Comptes Bancaires — REST · GraphQL · Data REST
Un microservice de comptes bancaires exposant le même domaine via trois interfaces — une API REST écrite à la main, une API GraphQL, et Spring Data REST auto-généré — avec couche DTO/mapper, documentation OpenAPI/Swagger et base H2.
Blockchain de Zéro — Spring Boot
Une blockchain pédagogique en Java/Spring Boot : blocs, pool de transactions (mempool), hachage SHA-256, minage Proof-of-Work et validation complète de la chaîne — le tout piloté par une API REST, avec des démos crypto AES et chiffrement asymétrique.
Système de Réservation de Sessions — Angular + Spring Boot
Application de réservation full-stack : une UI Angular 17 sur une API REST Spring Boot 3.3 (JPA, MySQL/H2) gérant utilisateurs, sessions réservables avec capacité, réservations avec suivi de statut, et membres de jury affectés aux sessions.
MicroBank — Web Service SOAP (JAX-WS)
Un web service SOAP avec JAX-WS : un endpoint « MicroBank » standalone exposant conversion de devises et opérations de compte, plus un client qui le consomme via un stub généré depuis le WSDL avec wsimport.
Gestion d'Hôpital — Spring MVC + Security
Une application web complète de gestion de patients : Spring MVC + Spring Data JPA + Thymeleaf avec recherche paginée, validation de formulaires, et Spring Security 6 (login formulaire, remember-me, autorisation par rôles USER vs ADMIN).
Patients d'Hôpital — Spring Boot MVC + Thymeleaf
Une application web Spring Boot MVC + Thymeleaf ciblée : table de patients paginée (3 par page), recherche par nom via requête dérivée, suppression avec confirmation, et layout décoré partagé — initialisée par un CommandLineRunner gardé par profil et testée avec MockMvc sur H2.
Domaine Hôpital — Relations Spring Data JPA
Une étude de modélisation Spring Data JPA sur un domaine hospitalier : entités Patient, Medecin, RendezVous et Consultation reliées par @OneToMany, @ManyToOne et @OneToOne, couche service transactionnelle, repositories dérivés et endpoint REST.
Injection de Dépendances & IoC — Quatre Techniques
Une étude pratique de l'inversion de contrôle en Java : le même découpage DAO/métier câblé de quatre façons — injection par setter manuelle, chargement dynamique par réflexion depuis un fichier de config, config conteneur Spring XML, et scan d'annotations Spring (@Component/@Autowired).
Calculatrice Scientifique & Labos DOM — JS Vanilla
Un ensemble de mini-projets HTML/CSS/JavaScript sans dépendances couvrant les fondamentaux : une calculatrice scientifique en CSS Grid (trigo, log, racines, π/e), plus des exercices de manipulation du DOM et de gestion d'événements (échange de champs, arithmétique, IMC). Aucun outil de build — il suffit d'ouvrir dans un navigateur.
Besoin d'un ingénieur IA ou data scientist ?
Je conçois des modèles ML sur mesure, des agents IA, de la vision par ordinateur et de l'automatisation — de l'idée à la production.